
以客户为中心,提供定制化或一站式的全栈解决方案,赋能千行百业

GPU计算是指利用图形卡来进行一般意义上的计算,而不是传统意义上的图形绘制。时至今日,GPU已发展成为一种高度并行化、多线程、多核的处理器,具有杰出的计算功率和极高的存储器带宽。如图:
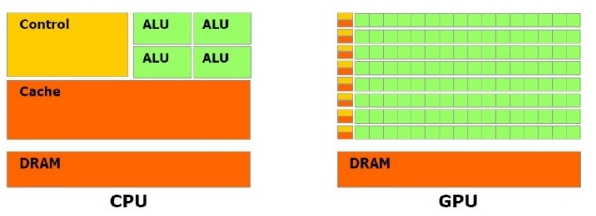
具体地说,GPU专用于解决可表示为数据并行计算的问题——在许多数据元素上并行执行的程序,具有极高的计算密度(数学运算与存储器运算的比率)。由于所有数据元素都执行相同的程序,因此对精密流控制的要求不高;由于在许多数据元素上运行,且具有较高的计算密度,因而可通过计算隐藏存储器访问延迟,而不必使用较大的数据缓存。
数据并行处理会将数据元素映射到并行处理线程。许多处理大型数据集的应用程序都可使用数据并行编程模型来加速计算。在 3D渲染中,大量的像素和顶点集将映射到并行线程。类似地,图像和媒体处理应用程序(如渲染图像的后期处理、视频编码和解码、图像缩放、立体视觉和模式识别等)可将图像块和像素映射到并行处理线程。实际上,在图像渲染和处理领域之外的许多算法也都是通过数据并行处理加速的——从普通信号处理或物理仿真一直到数理金融或数理生物学。在上述领域,GPU计算已经获得了成功的应用,并取得了令人难以置信的加速效果。
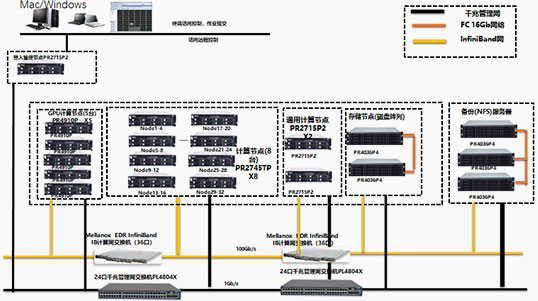
整套GPU高性能方案采用通用CPU和专用GPU均衡设计,既保证了GPU的处理性能,又兼顾了通用CPU的计算能力。既保证了适合GPU的高并行度计算应用的需求,同时也保证了非高并行度应用和尚未进行GPU移植的应用需求。并且由于GPU具有较高浮点计算性能的特点,方案中使用GPU作为主体计算资源,将图形处理器引入到高性能计算领域。

宝德服务器

宝德自强®












 4008-870-872
4008-870-872
